

Выделили главных игроков, обозначили проблемы и перспективы.

}

Мы создаем и продвигаем свои открытые решения, проводим профильные мероприятия, предоставляем полезные материалы — и помогаем делать это другим. В составе сообщества около 1000 участников.
Большинство из них уже в нашем телеграм-чате — в нем можно связаться с нами и задать любые вопросы по исследованию.




Какие проекты они используют сами?
О проблемах и историях успеха.
Что есть и чего не хватает?
Про актуальное состояние и перспективы опенсорса в эпоху ИИ.
-
Максим Савченко
Сбер, Управляющий директор, руководитель Центра инструментов машинного обучения Лаборатории AI
-
Сергей Бережной
Яндекс, Директор по взаимодействию с разработчиками
-
Александр Чиков
Т-Банк, Тимлид
-
Юрий Кацер
Рокет Контрол, DS team lead
-
Александр Сидоров
Wildberries, Head of Data Science
-
Александр Волынский
VK, Технический менеджер Cloud ML Platform, архитектор VK Cloud
-
Алексей Смирнов
CodeScoring, Founder & CEO
-
Александр Нозик
МФТИ, Директор центра научного программирования














Опыт прикладных исследований более 15 лет, выпускник МФТИ (2004, теоретическая физика), ШАД Яндекс (целевая группа Сбербанка, 2014), Лондонская школа бизнеса (2019).

В Яндексе с 2005 года. В разных ролях успел поработать над поиском, почтой, поиском по блогам, платформой Я.ру, картинками, видео, внутренними инструментами и многими другими сервисами. Развивает технологии и инструменты для создания сайтов. Один из двух соавторов методологии БЭМ. В последнее время занимается вопросами удобства разработки, найма и адаптации, обучения, Tech PR, выступает в роли технического эксперта для конференций. Также занимается опенсорсом внутри компании.

Команда Александра разрабатывает опенсорсную библиотеку ETNA для работы с временными рядами, которая используется для решения внутренних задач. На основе этой библиотеки в компании также создают платформу AutoML для аналитиков, позволяющую автоматически строить прогнозы и выявлять аномалии в данных.
Лично занимается разработкой библиотеки и решением внутренних кейсов, в то время как отдельная подкоманда фокусируется на создании платформы. Подавляющее большинство инструментов, которые использует, опенсорсные.

Эксперт в области машинного обучения и анализа данных для промышленных задач. За последние восемь лет прошел путь от начинающего дата-сайентиста до руководителя направлений в российских промышленных компаниях. Занимаеся решением задач, связанных с поиском аномалий, прогнозированием остаточного ресурса оборудования, оптимизацией технологических процессов.
Поработал с данными таких компаний, как Норникель, НЛМК, ММК, ТМК, ЧТПЗ, ПМХ, Росатом, ГПН и Сибур, участвовал в решении более 30 реальных задач. Сейчас является руководителем направления задач оптимизации производства в Рокет Контрол, руководителем группы предиктивной аналитики в НГУ, преподает и развивает DS в промышленности.

С 2023 работает Head of DS в Wildberries ― в том числе помогает перевести поиск сразу на мультимодальные трансформеры.

Отвечает за ML Platform в VK Cloud. Большинство решений строит на базе опенсорса.

Основатель компании Profiscope, генеральный директор и руководитель продукта CodeScoring. Это продукт, который собирает информацию про мировой опенсорс и сопутствующие данные для обеспечения оперативной проверки безопасности в рамках SDLC. Компания анализирует практически весь мировой опенсорс, за исключением китайского и отдельных решений на частных площадках. Занимается целеполаганием, руководит продуктом.

Руководитель российского Kotlin-сообщества, один из основных авторов и популяризатор опенсорс-экосистемы Kotlin for Science.
Из специфичных для нашей библиотеки могу выделить: statsmodels, optuna, hydra, pytorch-lightning, wandb, black, mypy, isort, flake8, pytest
Для задач ML/MLops - CatBoost, TensorFlow, MLflow, Kubeflow. Также используются ClickHouse, Различные решения от Apache - Airflow, Superset, Nifi. Можно также назвать Trino, k8s, Greenplum, Redis.
В области глубокого обучения мы используем Torch. Для работы с данными применяются Apache Spark, Greenplum и ArenaData. В машинном обучении мы предпочитаем такие инструменты, как Optuna, LightGBM и CatBoost.
Проприетарный стек (Java / SAS) внутри компании был заменен на open-source на Python в 2013-2014 годах.
В качестве других примеров перехода на опенсорс можно отметить использование Greenplum вместо Teradata и Postgres вместо Oracle.
Сейчас становится важным добавление интерпретируемости в общий стек, и здесь на помощь приходит библиотека SHAP, которая уже стала стандартом. Также стоит отметить, что в DL-проектах почти всегда используются TensorFlow и PyTorch.
При обсуждении продуктивизации как этапа в разработке машинного обучения важно упомянуть фреймворки Flask и FastAPI, которые необходимы для большинства простых проектов.
Безусловно, среди используемых продуктов выделяются линейка продуктов Яндекса, ClickHouse, продукты Apache. Сейчас наблюдаю тренды на использование Trino. Neo4j тоже регулярно встречается. Многие живут с MongoDB.
Для задач связанных со сбором и анализом данных мы используем PostgreSQL, ClickHouse, Airflow. Это база. Для фронтенда используем качественный фреймворк ant.design, для бэкендов Django/FastAPI. Основную функциональность наших продуктовых решений разрабатываем самостоятельно.
Например, мы решаем задачи оптимизации в режиме реального времени, чтобы выбирать наиболее эффективные методы управления. Для этого мы использовали солверы, которые обеспечивают высокую скорость и точность. Однако единственным доступным нам решением, которое давало хорошие результаты, был платный проприетарный солвер.
Бывают и проблемы с пригодностью лицензий для корпоративного применения — так, решая задачу из области компьютерного зрения, пришлось перейти с модели YOLO (AGPL v. 3) на китайский фреймворк MMlab (с лицензией Apache 2.0).
Мы сами активно занимаемся внесением тикетов и пулл-реквестов в чужие проекты ― где-то успешно, где-то нет. Если нет, патчим самостоятельно и синхронизируемся с апстримом.
Например, мы разработали систему контроля версий, основная задача которой — масштабирование на огромные монорепозитории. Когда мы принимали решение о переходе в опенсорс, у нас возникли сомнения: «Кому это нужно, кроме Яндекса с его обширным репозиторием?» Не каждая компания располагает таким объемом кода, и не все используют монорепозитории в своей модели разработки. В результате многие аспекты нашей системы оказываются избыточными для большинства пользователей.
Кроме того, сотрудничество с другими командами оказывается сложным из-за понятийного разрыва. Мы решаем задачи различного масштаба и типа, что затрудняет взаимодействие.
Использование популярных фреймворков также создает свои трудности: писать ишью становится бесполезно, так как в таких системах накапливаются тысячи нерешенных запросов, которые остаются без внимания.
Бывает сложно договориться. Приведу пример: однажды у нас возник вопрос о возможности перехода на Playwright ― это опенсорс-инструмент для визуального тестирования интерфейсов. Мы провели обсуждения с командой Playwright, однако, к сожалению, наши взгляды на сотрудничество не совпали. Им не требовалось то, что было необходимо нам. Например, нам нужно тестировать в более широком диапазоне браузеров, чем это предусмотрено в самой системе Playwright, а также учитывать большой объем и поток изменений, с которыми мы работаем.
Вообще, важнее качество продукта и его зрелость, а не принадлежность к open source.
- Плохая документация (Faiss, PaxML, Praxis): документация этих библиотек оставляет желать лучшего, и разобраться в их работе без чтения исходного кода становится крайне сложно. Для библиотек-биндингов не всегда помогает даже изучение кода.
- Непрозрачность (CatBoost, Ruptures): хотя документация этих библиотек может быть качественной, она часто представлена на слишком высоком уровне абстракции. Это затрудняет понимание нюансов, что может быть критически важным при интеграции и настройке.
- Сложности в поиске ответов на вопросы: на таких платформах, как Stack Overflow или в GitHub Issues, обсуждения и решения проблем в основном сосредоточены вокруг крупных библиотек, что затрудняет поиск информации по менее популярным инструментам.
Поскольку мы сами разрабатываем библиотеку, у нас есть определенный уклон в сторону изучения чужого кода. Благодаря этому в большинстве случаев мы можем самостоятельно решать возникающие проблемы.
Тем не менее, были несколько случаев, когда мы обращались к команде разработки с просьбой внести небольшие изменения, такие как обновление версии зависимости или добавление лицензии. Однако такие ситуации скорее являются исключением, чем правилом.
Наша команда не организует семинары, но у нас есть планы по созданию курса на базе нашей библиотеки. Я слышал о курсе по LightAutoML на ODS, который может быть интересен.
Базовые навыки работы с опенсорсом я в основном получал в рамках курсов по машинному обучению и Data Science, где часто рассказывают о различных инструментах. Обычно достаточно изучить документацию и демо-ноутбуки, чтобы начать.
Я сам делал доклад на секции Open Source DataFest и посещал Yandex Open Source Jam. О других активностях не слышал, хотя в рамках PyData и подобных мероприятий проводятся доклады по опенсорсу.
В рамках русскоязычного сообщества было бы полезно внедрить такие форматы:
- Представление своих инструментов: про новые библиотеки от русскоязычного сообщества знают далеко не все даже из профсообщества. Было бы замечательно создать площадку, где можно было бы ознакомиться с этими инструментами. Yandex уже сделал шаг в этом направлении, предложив гранты.
- Мастер-классы по использованию инструментов: часто документации по инструментам не хватает для их качественного использования. Очень интересно было бы услышать о нюансах от опытных пользователей.
Тем не менее, у нас есть позитивный опыт научно-исследовательской работы (НИР) с университетами, такими как ИТМО и Сколтех. Мы реализовали проекты (примеры ― SLAMA, GLAMA и PyBoost), которые включают в себя создание туториалов к библиотекам и обучающие курсы. Мы активно привлекаем студентов (и не только) к доработке проектов через НИР, стажировки и практики, что также включает командные проекты. Мотивацией для участия в таких инициативах служат научная деятельность и публикация статей.
Мы также развиваем партнерство с различными компаниями и командами, такими как Intel, JB, Acronyx, Arenadata, ИТМО и Яндекс, что позволяет нам продвигать технологии и расширять сотрудничество.
В России, к сожалению, очень мало опенсорсеров и разработчиков системного программного обеспечения, а также специалистов в области машинного обучения. Примером этой проблемы может служить отсутствие аналогов типовых CAD-решений, таких как SolidWorks, в инженерном ПО.
Что касается общества, то можно почитать канал «Open Source Россия», в котором тысяча мнений и все ищут общий язык. В этом отражение мирового опенсорса, это не только российская особенность.
Полезные курсы попадаются на Stepik и подобных платформах. В опенсорсе есть амбассадоры ― например, Никита Соболев, который делал значимые доклады на важные темы, или Денис Петухов, который делится опытом работы с опенсорсом и рассказывает о том, каково это на практике.
Как только появляются мероприятия, я всегда стараюсь их поддерживать ― например, Data Fest от ODS. Мы также занимаемся созданием отчетов по состоянию опенсорсных и активно подключаемся к различным «движухам» в этой области, в том числе в статусе партнеров.
В России, в основном, это энтузиазм отдельных сотрудников. Я знаю людей, которые выступают на специализированных конференциях, но в целом ситуация довольно плачевная. Такие инициативы не происходят систематически, и компании зачастую не развивают эти направления.
Я иногда выступаю на конференциях, посвященных теме data science, с основным акцентом на анализе временных рядов и применении методов data science в промышленности.
В России не хватает качественных научных конференций. Те конференции, которые существуют, зачастую ориентированы на студентов, которым нужно выполнить научно-исследовательскую работу, и их уровень оставляет желать лучшего. Также мало технических конференций, аналогичных PyCon. К сожалению, «маркетинговых» мероприятий— гораздо больше. Это может быть связано с тем, что деньги на науку не всегда остаются, а, чтобы создать с нуля и наладить процесс, особенно в науке, надо инвестировать, можно посмотреть на создание Сколтеха и на то, сколько инвестируют в науку топовые международные корпорации.
Не хватает глубоких форматов для опытных специалистов уровня Senior и выше, таких как тематические встречи, митапы по сложным вопросам, кворумы и открытые дискуссии, возможно, для меньшего числа участников. Нам нужны мероприятия, где можно в более живом формате пообщаться с авторами опенсорс-проектов и наладить контакт.
Мы организовали Open Source Jam, но эта тема нишевая, аудитория не так велика. Примеры международных конференций подобного уровня — FOSDEM и Open Source Summit — но, к сожалению, мы их пока не посещали.
За ClickHouse огромное спасибо Алексею Миловидову - это хороший инструмент, создание которого стало возможным именно в недрах Яндекса.
Что касается корпоративного сектора, то Сбер заметно выделяется. Также в этой области активно участвует Т-банк. В сфере промышленности можно было упомянуть ГПН, но они уже сократили участие в открытых проектах, хотя раньше были довольно активны. Яндекс с CatBoost, безусловно, занимает одну из лидирующих позиций. ClickHouse также стал стандартом в стеке.
Компании, такие как Норникель, Полюс, Росатом и другие, никогда не выкладывают свои специфические продукты в опенсорс. В основном, это либо небольшие проекты от энтузиастов, либо неясные инициативы, которые представляют собой каплю в море.
Мы значительно отстаем в разработке собственных решений — известные российские разработки в области машинного обучения и анализа данных можно пересчитать по пальцам одной руки. Это, похоже, связано с тем, что мы привыкли использовать уже готовые решения, как закрытые, так и открытые, и у нас не хватает времени на создание сложных внутренних разработок, которые затем можно было бы выложить в опенсорс.
Тем не менее, культура использования опенсорсных инструментов у нас хорошо развита. Сложно сказать, что именно изменилось за последние пять лет, так как я сам слежу за этой областью не более трех лет. Однако в рамках моего домена появилось множество библиотек с различной спецификой, и самому старому фреймворку уже около пяти лет. Похоже, что такой тренд наблюдается и в других областях: за последние пять лет для каждой задачи был создан набор качественных открытых инструментов.
Основным драйвером этого процесса, по-видимому, являются крупные технологические компании. У них достаточно экспертизы и ресурсов для создания собственных инструментов и их продвижения на рынок, в то время как разработки от энтузиастов часто остаются незамеченными.
Такие компании, как Amazon, могут пользоваться решениями сотен, а то и тысяч организаций. В России же наблюдается тенденция: "не хотим использовать чужое, будем делать свое". Вместо того чтобы выделять ресурсы на стартапы, компании предпочитают разрабатывать собственные решения.
Одной из серьезных проблем является монополизация рынка: многие компании разрабатывают решения in-house, что раздергивает и без того ограниченные ресурсы. Однако, если всех обязывать использовать одно и то же решение, ситуация может стать еще хуже.
Малый размер рынка усложняет внедрение результатов исследований и разработок, и при сопоставимом качестве это приводит к ухудшению ситуации. На энтузиазме много не сделаешь, и это блокирует развитие. Есть шанс для российских команд выйти на международный рынок, например, в Латинскую Америку, Африку или Индию. Ориентировать только на рынок внутри страны - малоперспективно.
Также, мощные облачные платформы и маркетплейсы предоставляют разработчикам опенсорсного программного обеспечения возможность напрямую выйти к конечным потребителям.
Необходимо стимулировать развитие облачных сервисов для конечных пользователей. Это позволит компаниям и командам сотрудничать с аналогами AWS или Azure для машинного обучения, поставляя опенсорсные компоненты и предлагая их на продажу.
В настоящее время у нас отсутствуют полные "цепочки" создания открытого программного обеспечения, что затрудняет его развитие и внедрение.
Я активно выступаю за создание нормальной площадки с адекватным спонсорством и диалогом, где будет понимание различий между корпоративным и частным опенсорсом. Компании зачастую не выкладывают свои ключевые разработки в открытый доступ.
При этом опенсорс — это глобальное явление, принадлежащее всему миру, и говорить о “российском опенсорсе” смысла нет.
С другой стороны инструменты разработки и исследований очень быстро окупаются. Они нужны всем, причем примерно одинаковые. Они часто не приносят денег сами по себе, так что их куда выгоднее делать сообществом один раз вместо того, чтобы повторять всю работу только для своей компании. Единственным существенным барьером на этом пути является "недальновидность" менеджеров среднего и нижнего звена. Для того, чтобы выполнить KPI, надо сделать свое и быстро. Вклад в опен-сорс - это же вроде как помощь конкурентам. Видно, что эта доктрина постепенно уходит в прошлое даже в России, хотя местами еще очень сильна.
Перспективы применения искусственного интеллекта в разработке и опенсорсе представляют собой сложную картину. Возможно, мы столкнемся с "хоккейной клюшкой" сингулярности, когда изменения произойдут стремительно и неожиданно. Есть вероятность, что мы доживем до технологической сингулярности в течение ближайших 10-20 лет.
У нас уже есть база в виде больших языковых моделей (LLM), но их необходимо контролировать и задавать им четкие задачи. Возможно, исчезнет часть рутинной работы программистов, а разработчики опенсорса займут более высокие позиции, такие как CTO или руководители разработки.
Я активно использую нейросетевые технологии и задаю вопросы о коде. В некоторых случаях результаты впечатляют, но в других я осознаю, что нам еще далеко до идеала. Да, произошел значительный скачок с развитием LLM, и они действительно способны значительно улучшить процессы. Однако я не уверен, что нас ждет дальнейший скачкообразный рост возможностей в ближайшее время.
- Появление инструментов для новых задач и доменов. Например, библиотеки для работы с большими языковыми моделями (LLM).
- Интеграция помощников на основе LLM в существующие инструменты. Например, в Functime уже реализованы подобные функции.
- Разработка библиотек для вычислений на альтернативных вычислительных устройствах, аналогичных GPU. Пока сложно сказать, какие именно это будут аналоги.
- Улучшение подходов к решению существующих задач. Мы наблюдаем переход от Pandas к более эффективным инструментам, таким как Polars и Rapids, а также демократизацию нейросетевых технологий.
- LLMOps — в настоящее время в индустрии активно внедряются эти практики, и, безусловно, появятся новые артефакты, связанные с их реализацией.
- Что касается альтернатив GPU и квантовых процессоров, мы сейчас сталкиваемся с ограничениями вычислительных мощностей, и нам необходим новый скачок в этой области.
- AutoML также становится все более актуальным, поскольку многие разработчики стремятся избежать решения однотипных задач, предпочитая автоматизировать процесс создания модели.
Самым важным аспектом является демократизация и доступность инструментов для решения практически любых задач. Еще пять лет назад многие проблемы приходилось решать с нуля, тогда как сейчас под каждую мелочь можно найти библиотеку на GitHub. Кроме того, к большинству качественных статей прилагается код, что значительно упрощает процесс обучения и внедрения новых решений. Это действительно замечательно, что такая культура уже сложилась.
Можно провести исторические аналогии:
- COBOL — высокоуровневая разработка на естественном языке, которая способствовала появлению системных программистов.
- SQL в 70-е годы также представлял собой разработку на естественном языке, что привело к возникновению программистов баз данных.
- Аналогично, с развитием профессии дата-инженеров.
- LLM (большие языковые модели) породили новую специальность — промпт-инженеров, и сейчас мы наблюдаем развитие автопромптинга.
Это рекурсивный процесс, в котором мы уходим все дальше.
Любая технология может снизить порог входа — например, библиотека scikit-learn с ее методами fit/predict. Однако человек с улицы не сможет создать что-то значительное, даже используя решения без кода. Да, появится новый мощный инструмент, но, проводя аналогию - написать "Войну и мир" только с помощью Word невозможно.
В новых реалиях можно будет привлечь к разработке опенсорса более доступных специалистов. Прогресс, безусловно, будет, но революции не произойдет. Например, полностью устранить галлюцинации в моделях вряд ли возможно.
Очень здоровский инкубатор ML-проектов в Open Data Science - мне кажется, что это главный источник в России “частного” опенсорса по теме ML. Корпорации и так сделают, а частники должны иметь некую точку, “котёл” в котором все варятся и откуда выходят. ODS, в этом плане, лучшая точка приземления. Всем желаю синергии с ними. Должна быть хорошая экосистема жизни разных сообществ, разных хабов.
Есть GitFlic, как аналог гитлаба, есть GitVerse как аналог гитхаба, - они наверное, в России и будут жить. Для меня сейчас больше вопрос в том, как дальше мировой опенсорс будет дробиться (если продолжит). Появляются частные площадки, есть китайские, будут российские, появятся и другие. Если страны сейчас пытаются объединиться, то площадки опенсорсные сейчас пытаются разъединиться - возможно этот тренд будет продолжаться ближайшие 10 лет.
Не хватает четких подходов к выстраиванию устойчивой экономики опенсорса. В основном гранты предоставляются на создание проектов, но не на их поддержку. Возникает вопрос: как измерять пользу и за что следует платить разработчикам?
Большие компании зачастую не знают, как правильно распределить свои средства для поддержки опенсорс-проектов, которые они используют. Отсутствие ясных пропорций между ними и механизмов поддержки создает дополнительные трудности в этой области.
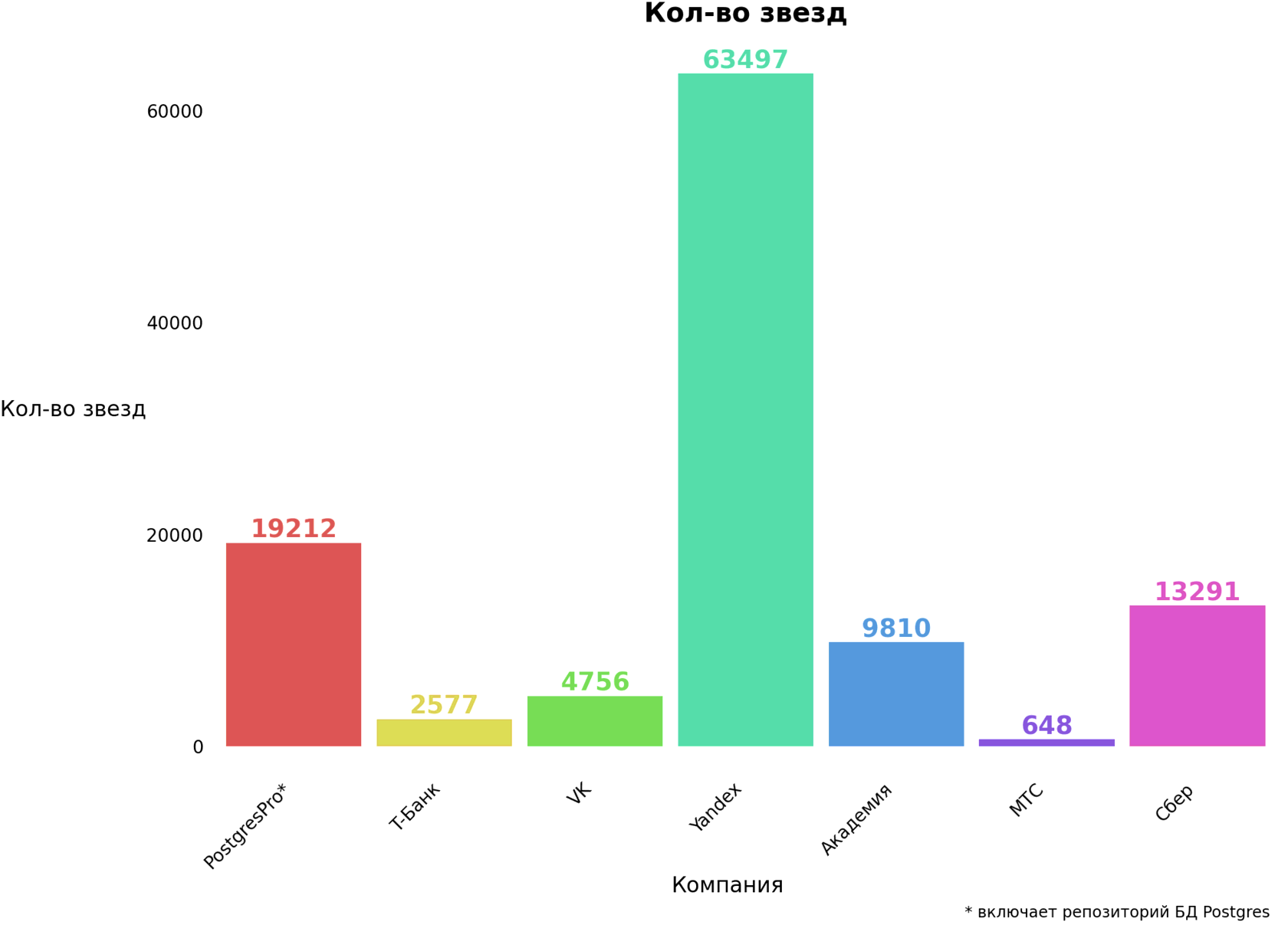
Поэтому следующая часть будет посвящена открытым репозиториям как таковым — автоматизированному анализу кода, ссылок на него, информации о профилях пользователей. Упор мы делали на платформу GitHub.

Но в этом исследовании мы трактуем «используемость» несколько уже (и не ожидаем, что эксперт зачитает нам весь requirements. txt). Речь о ключевых в стеке решениях, работы с которыми не сводится просто к их скачиванию.
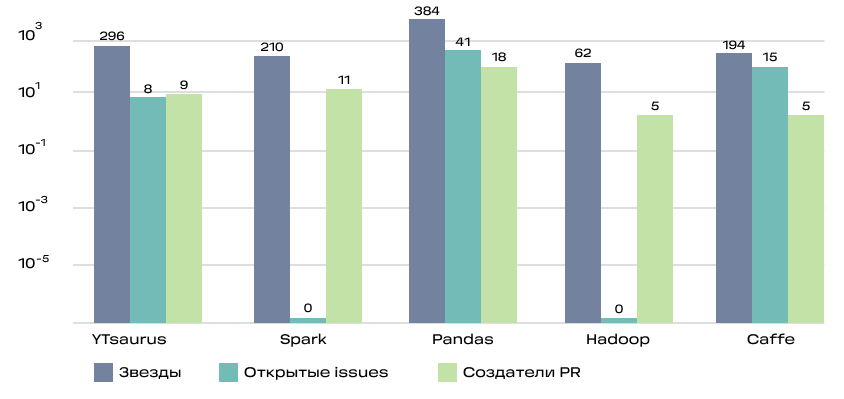
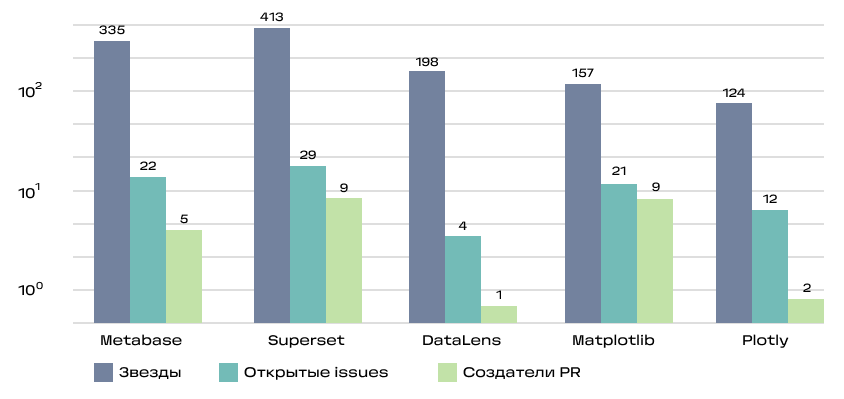
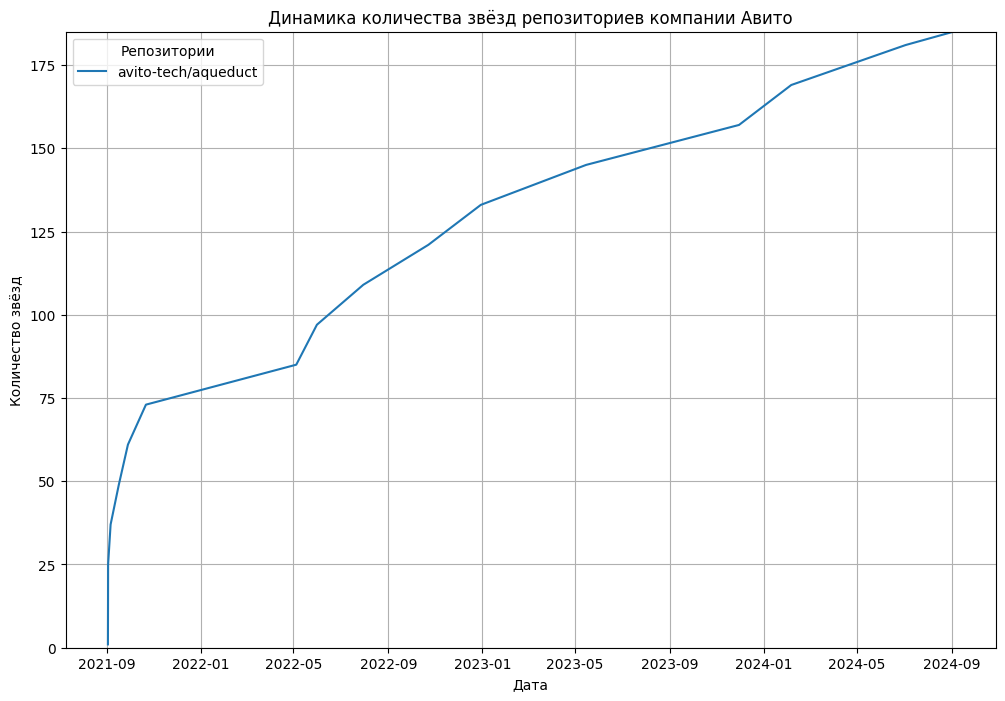
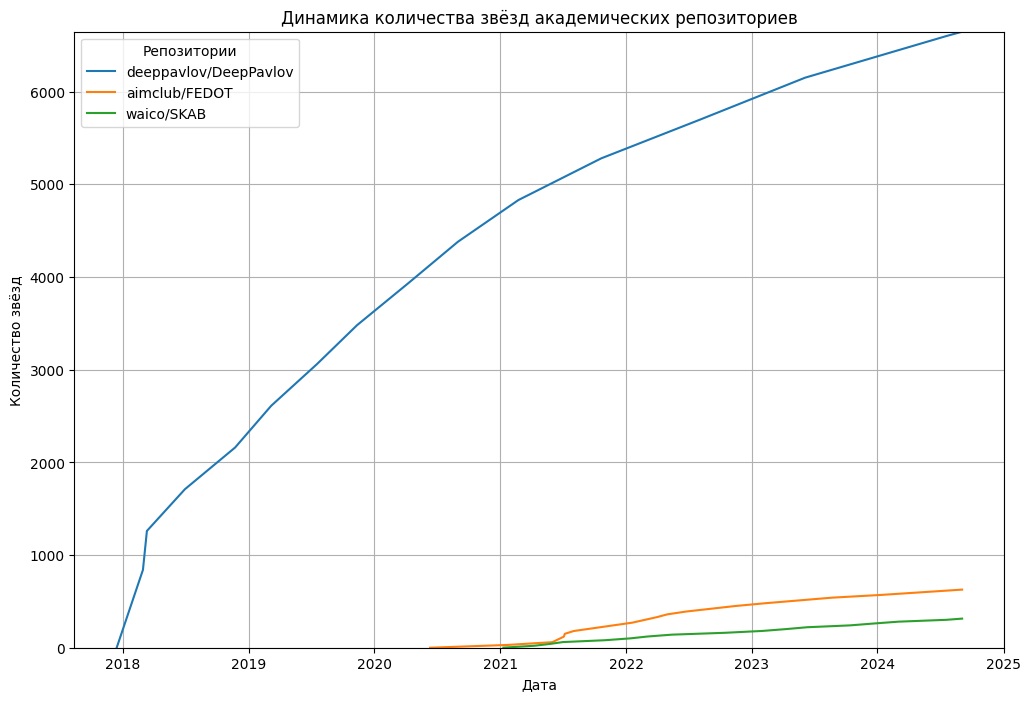
- количество звёзд (Stars)
- количество созданных issues (Issues)
- количество создателей PR (PR)
Именно таким сценарии использования нам наиболее интересны.
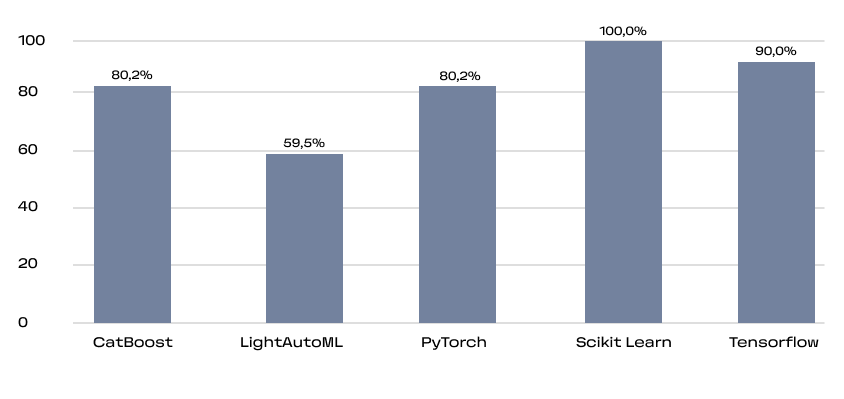
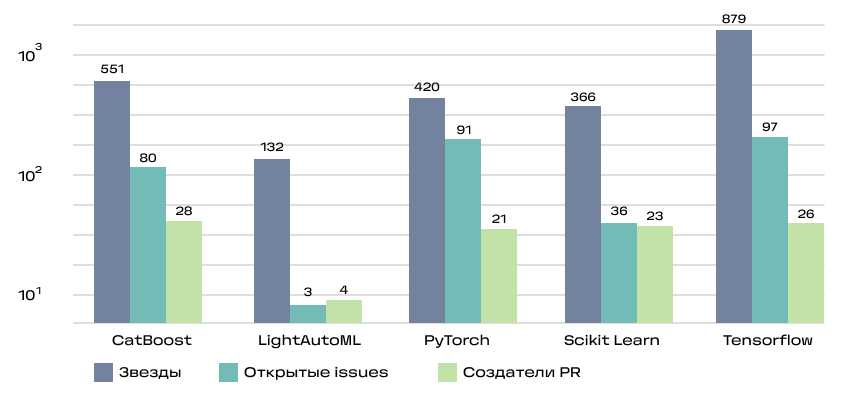


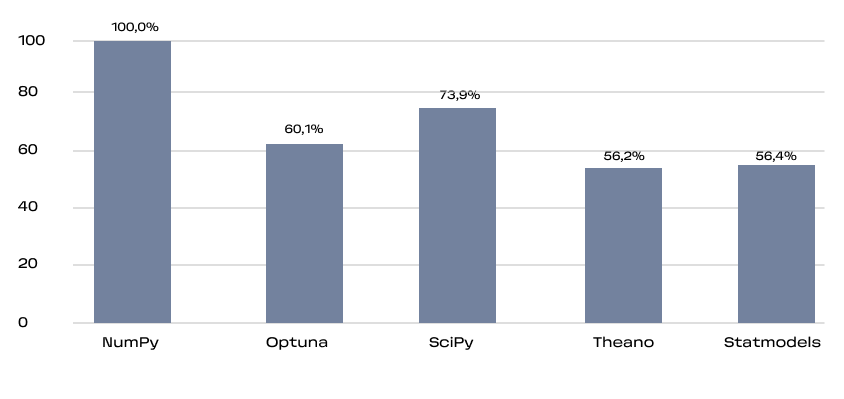
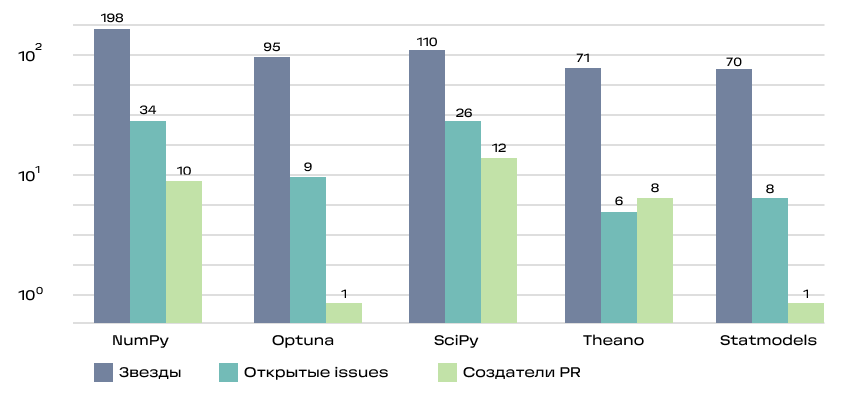
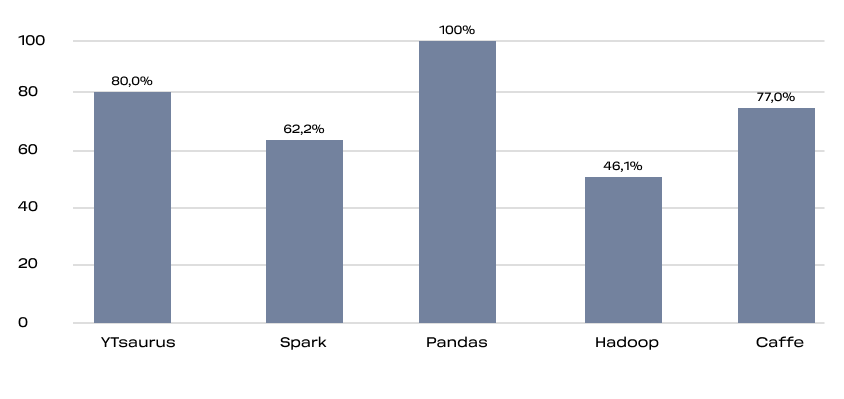
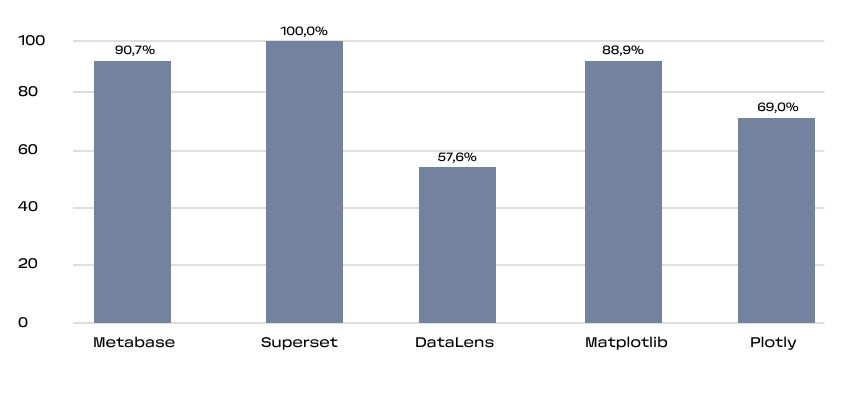
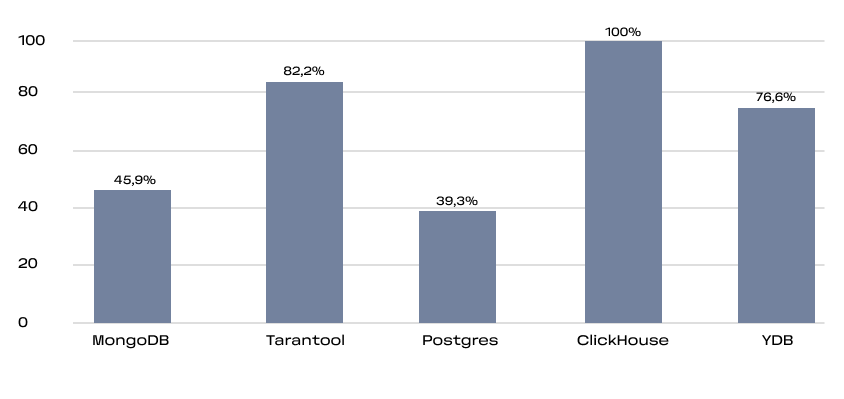
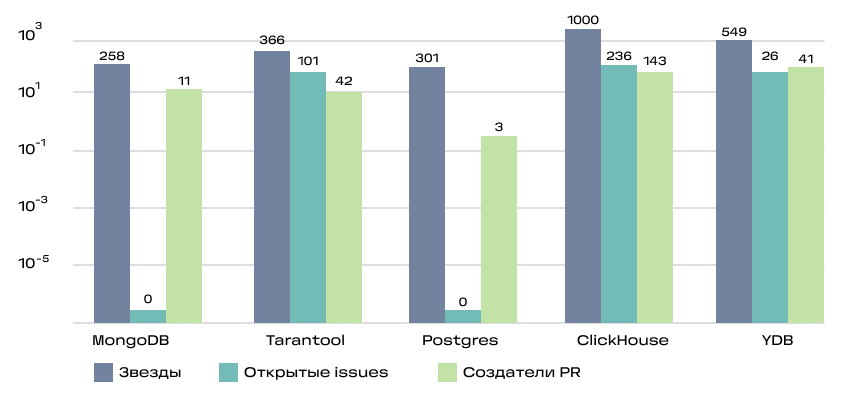
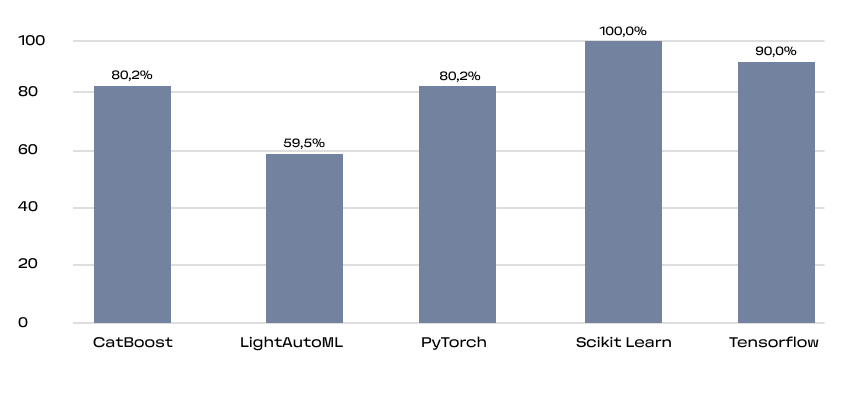
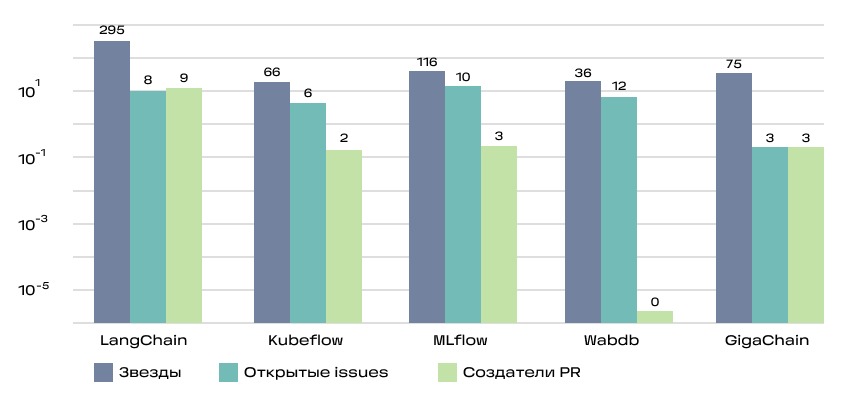
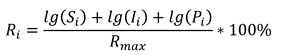
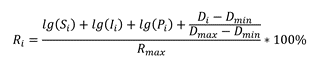
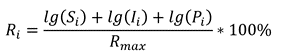
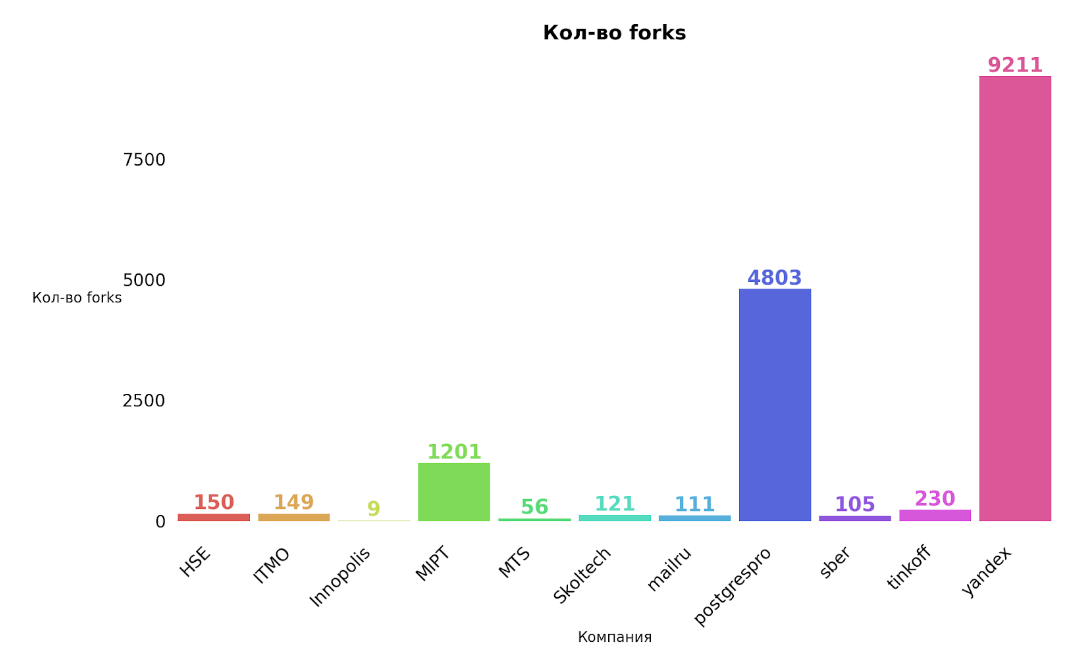
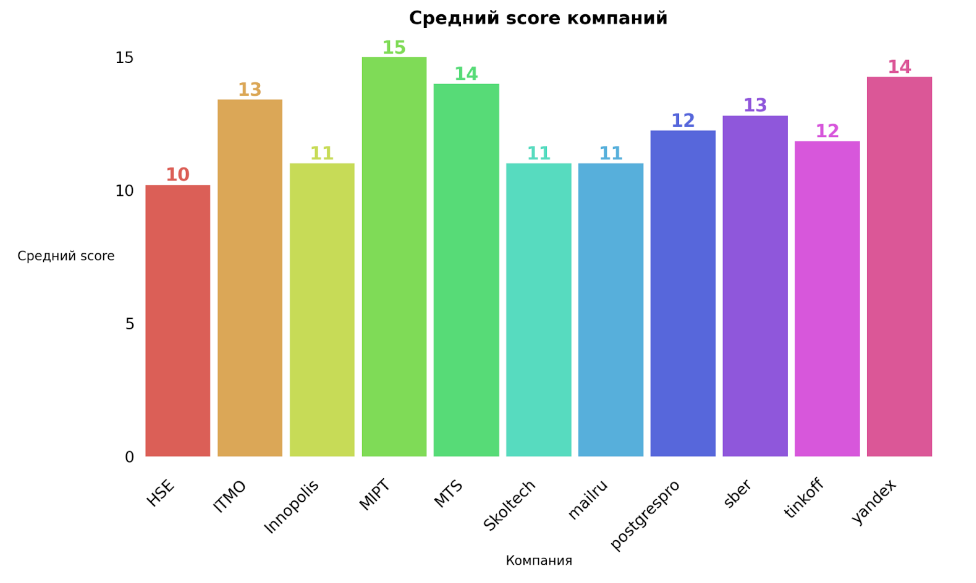
Это кумулятивная метрика, учитывающая как базовые вещи типа наличия readme и лицензии, так и частоту релизов, количество зависимых репозиториев и число контрибьюторов.
Для уравновешивания нишевых и массовых проектов SourceRank использует логарифмическую шкалу при расчёте некоторых её составляющих. Видно, что большинство активно используемых проектов проработаны на высоком уровне.



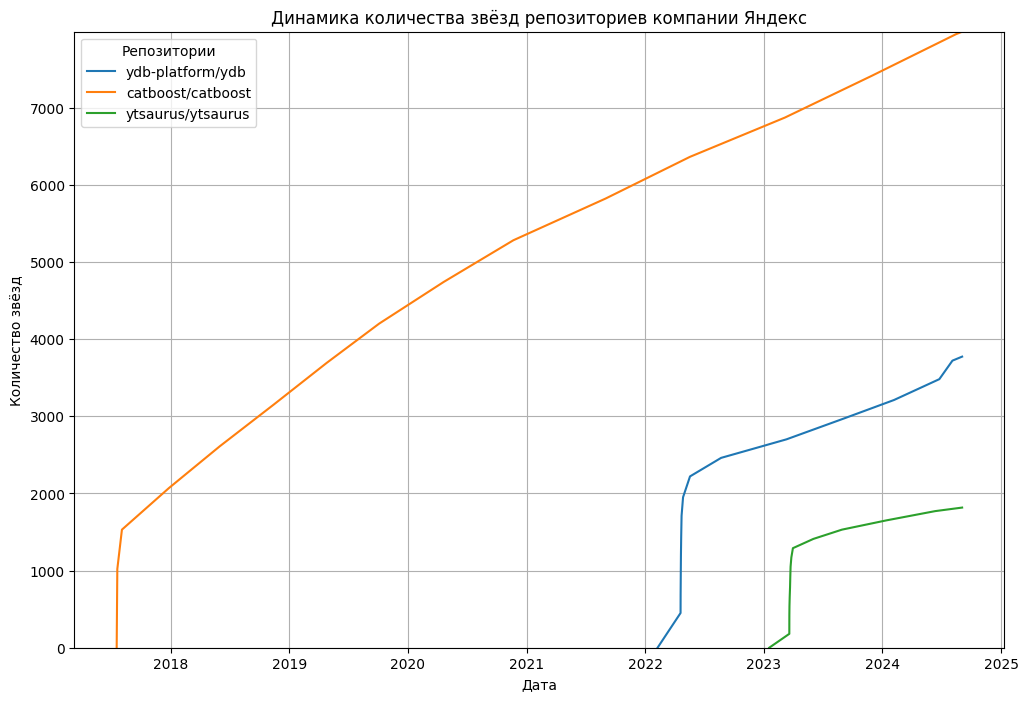
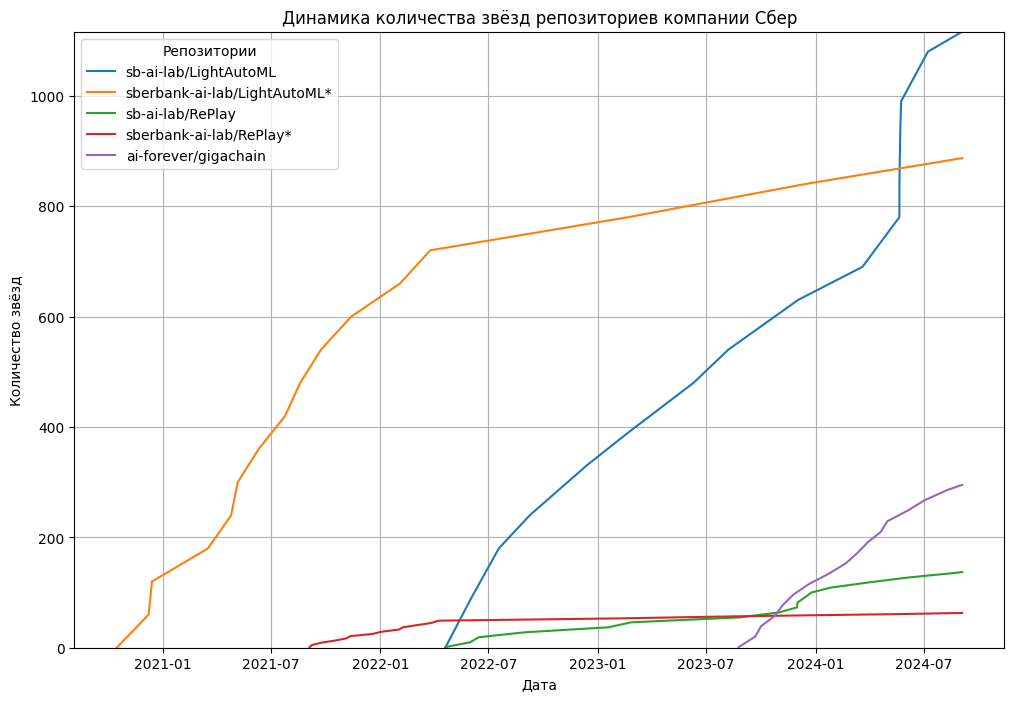

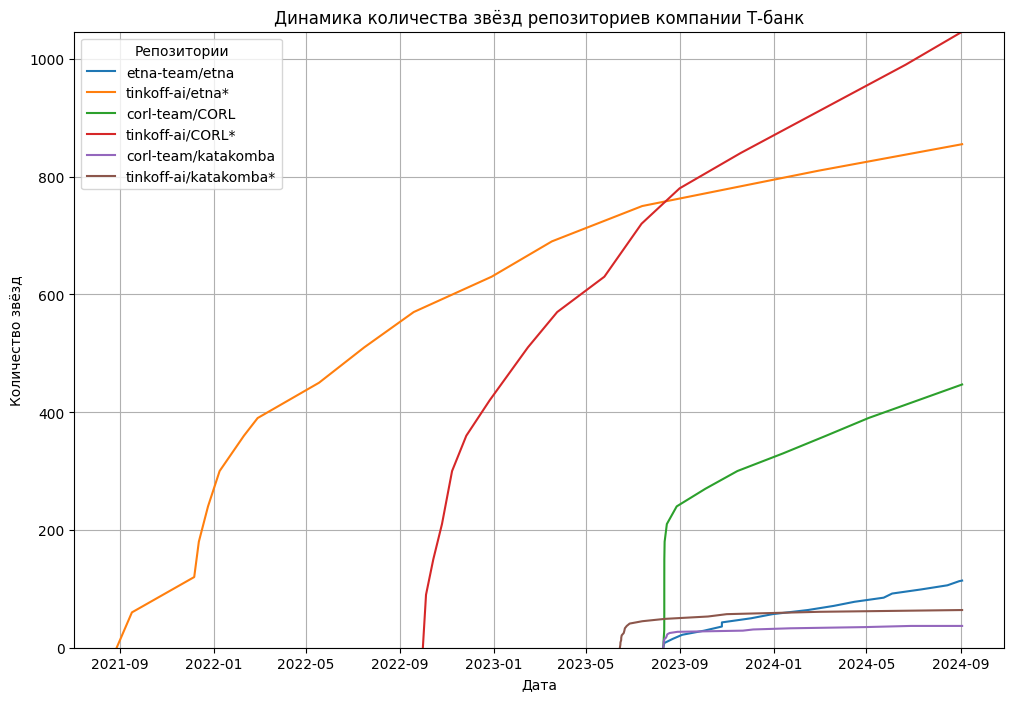

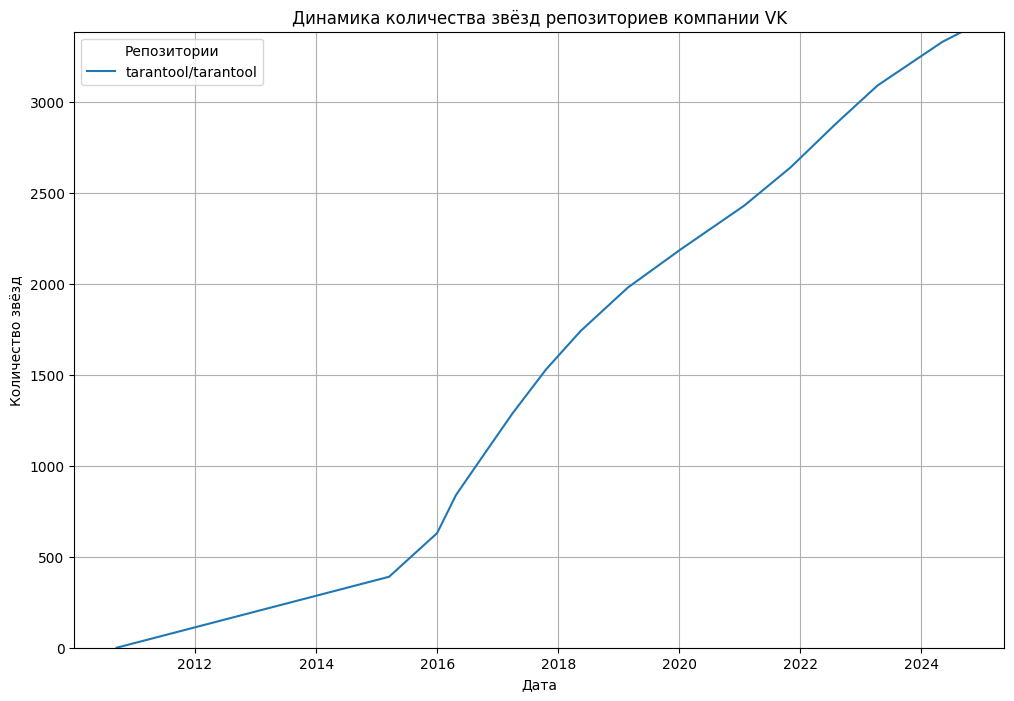

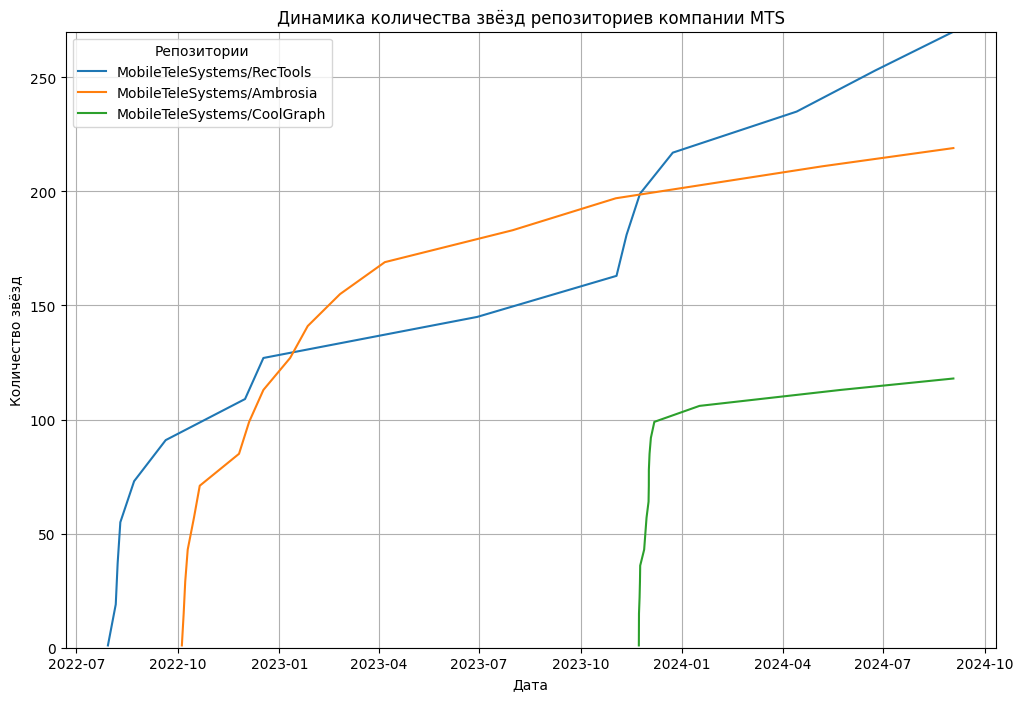

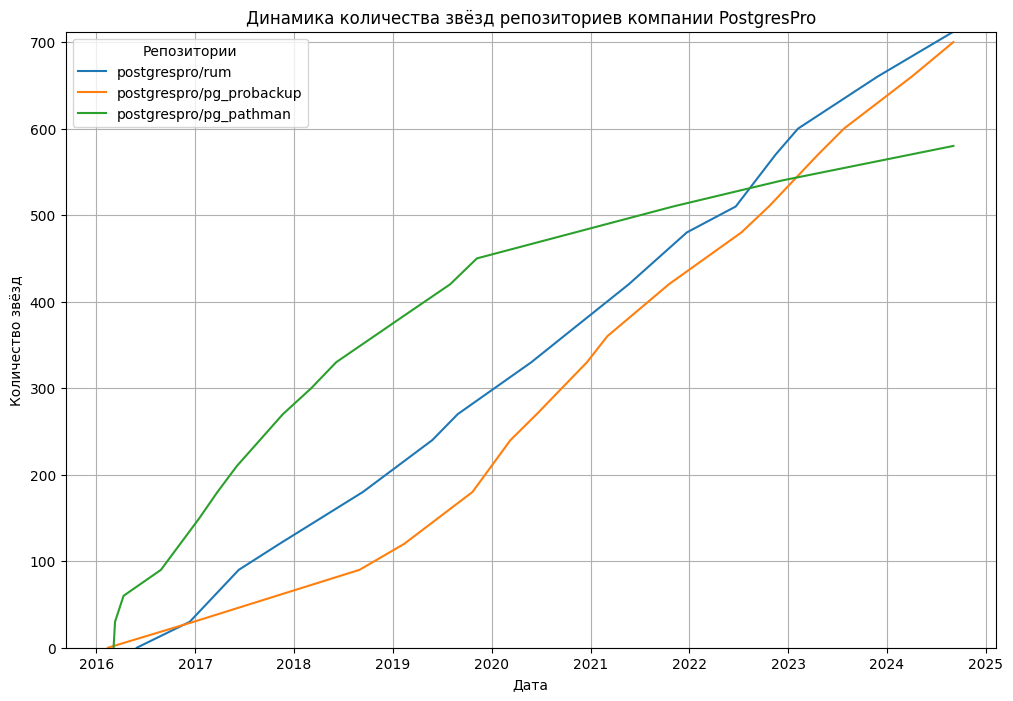


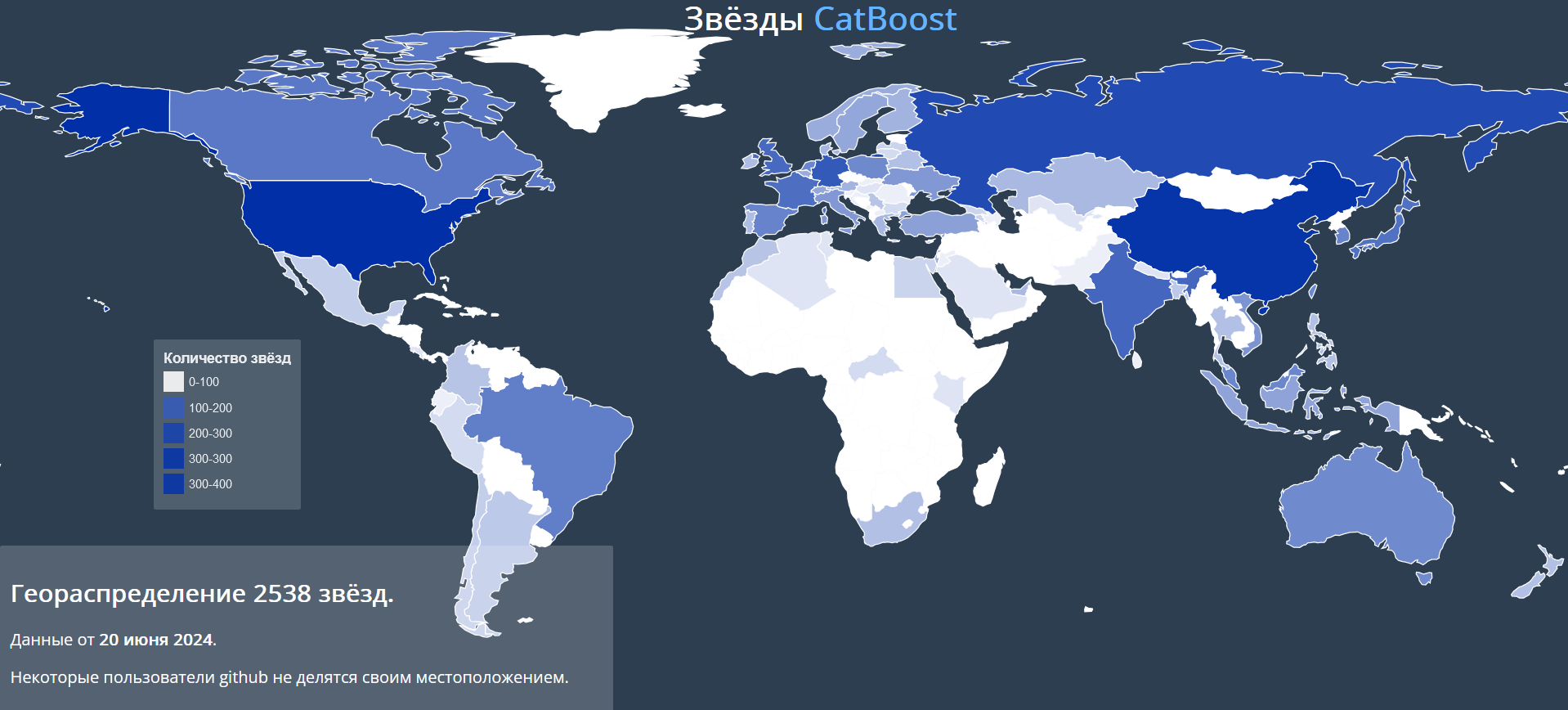
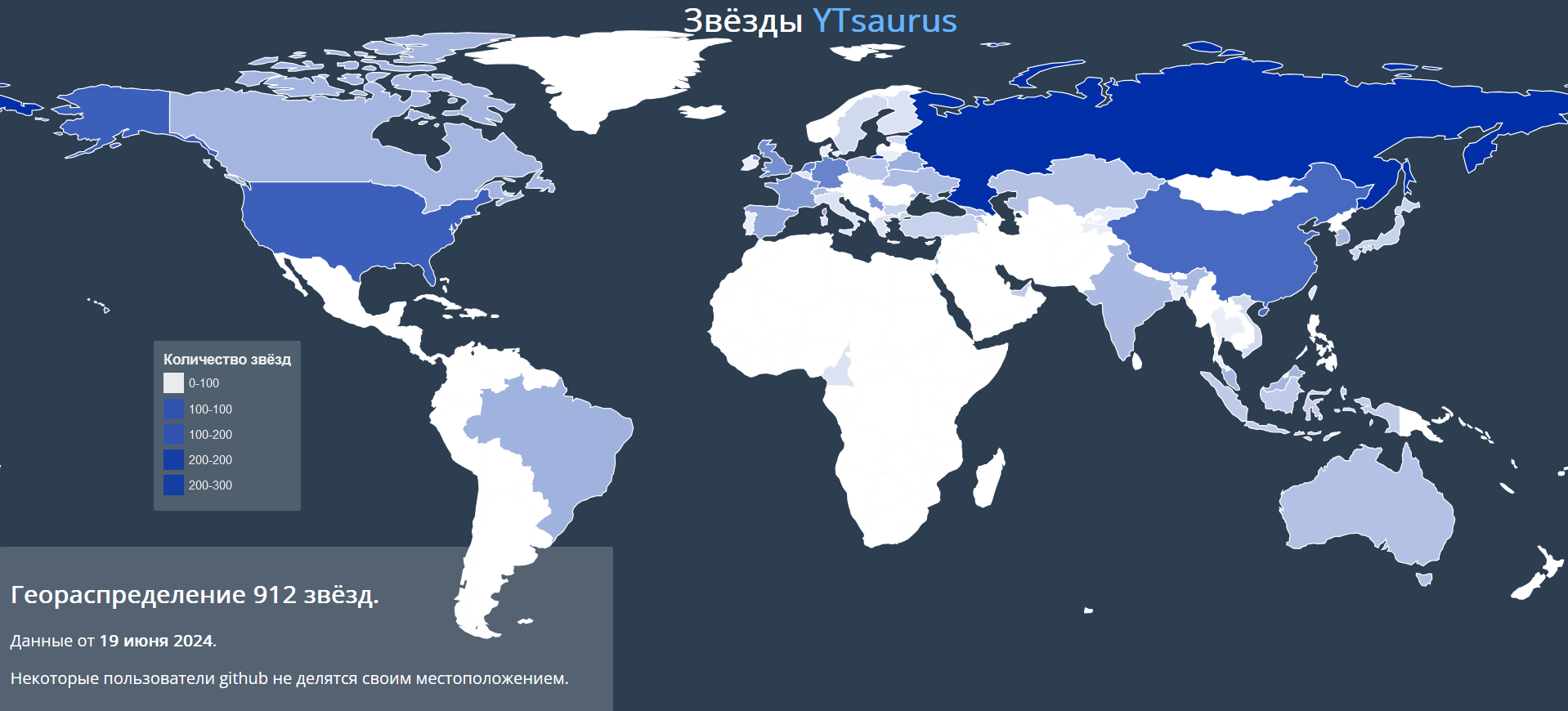
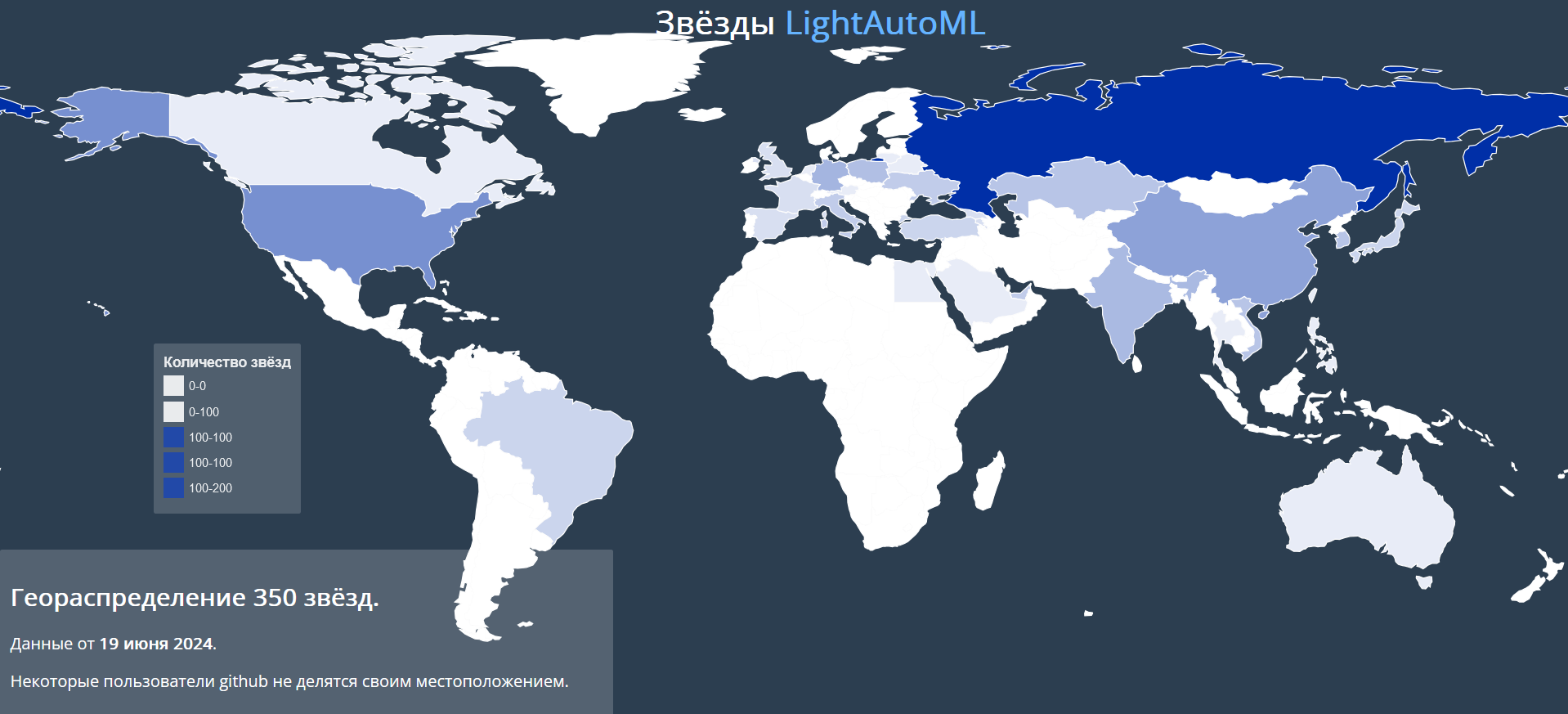
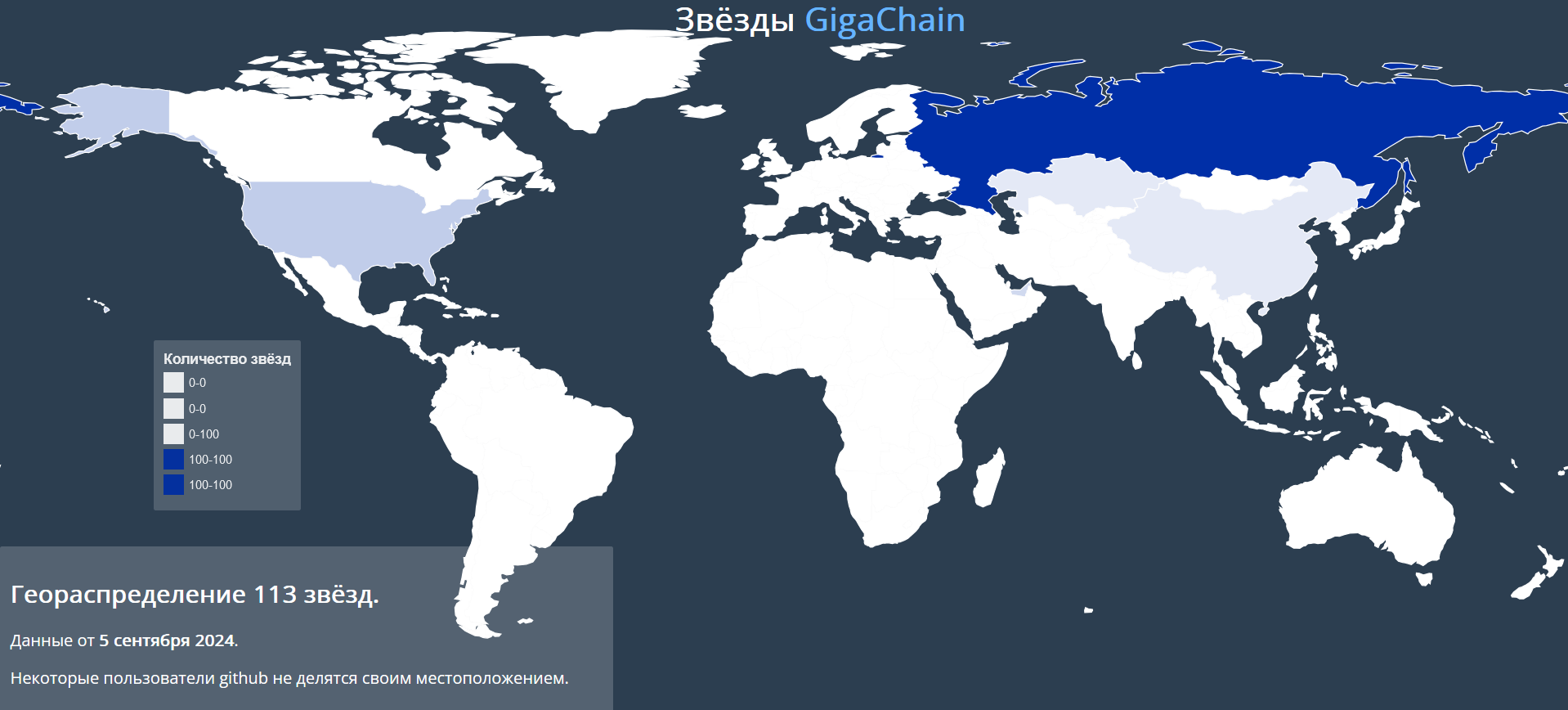
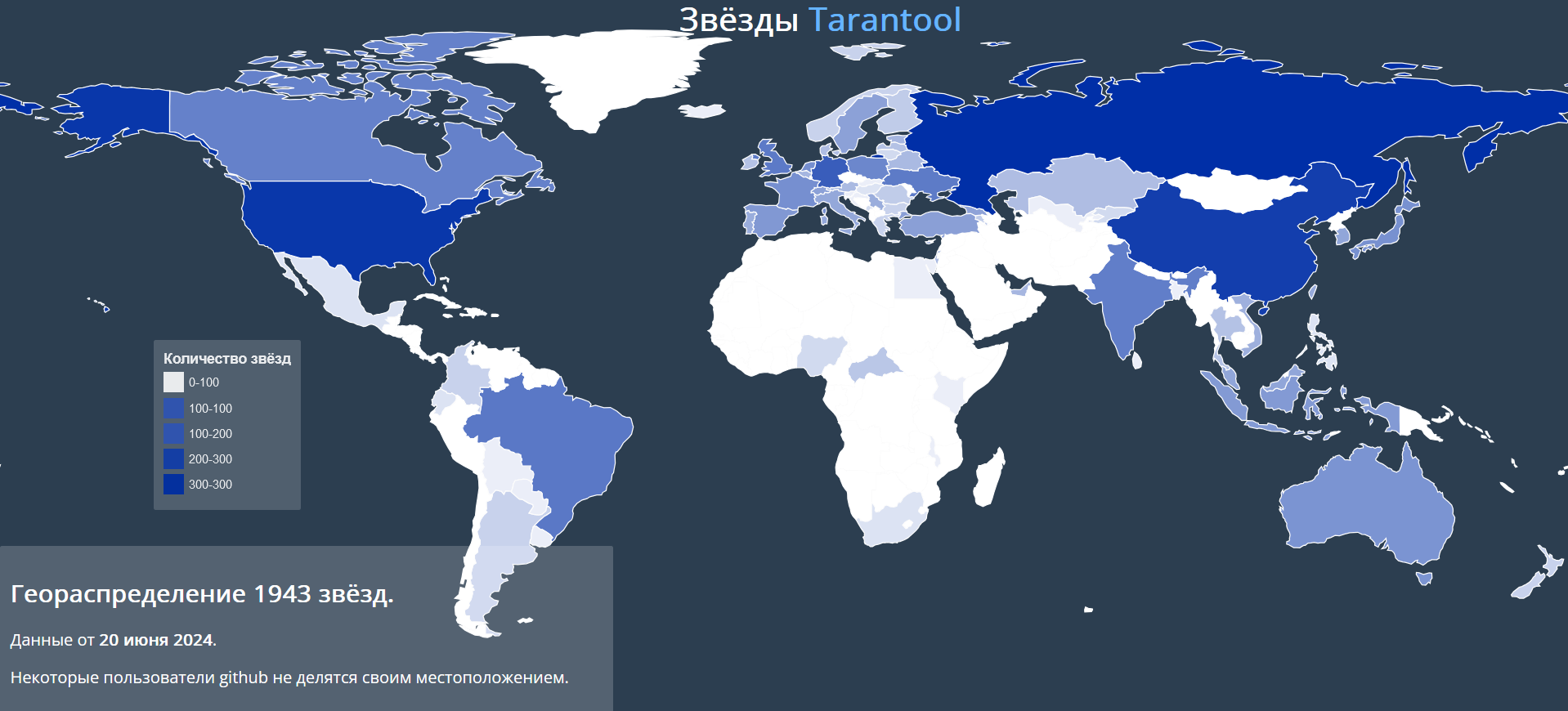
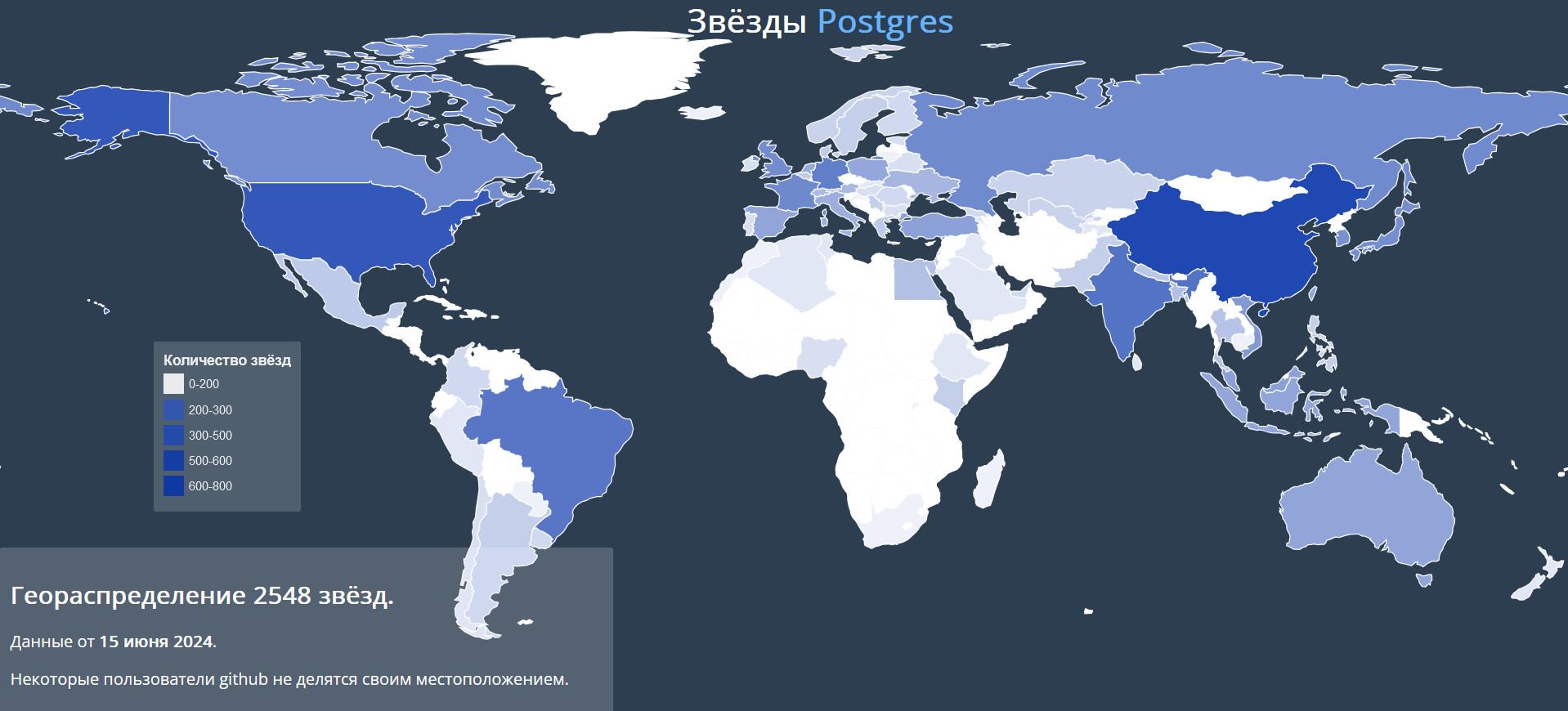
Группа ВК, AI Talent Hub,
Канал
Сайт, канал GOS, канал GoOpenSource
Меняются и схемы монетизации. Так, уже существуют сервисы поддержки авторов опенсорса (например, https://thanks.dev и https://blog.tidelift.com) - и стоит ожидать появления чего-то подобного и в России.
-
Николай Никитин
к.т.н, лидер сообщества ITMO OpenSource, руководитель группы научно-технического развития исследовательского центра «Сильный ИИ в промышленности»
-
Андрей Гетманов
опенсорс-энтузиаст, исследователь в области LLM и AutoML, сотрудник лаборатории композитного ИИ
-
Ирина Деева
к.ф.м.н, руководитель проекта по развитию открытого кода на ФЦТ, старший научный сотрудник ИЦ СИИП
-
Юрий Каминский
аспирант ФЦТ, исследователь в области LLM, руководитель студенческого опенсорсного клуба
-
Кирилл Федорин
Cтудент ИТМО
-
Иван Рубин
Cтудент ИТМО
197101, г. Санкт-Петербург, Кронверкский проспект, д. 49 лит. А
ИНН 7813045547
ОГРН 1027806868154
Разработка © 2024 Университет ИТМО